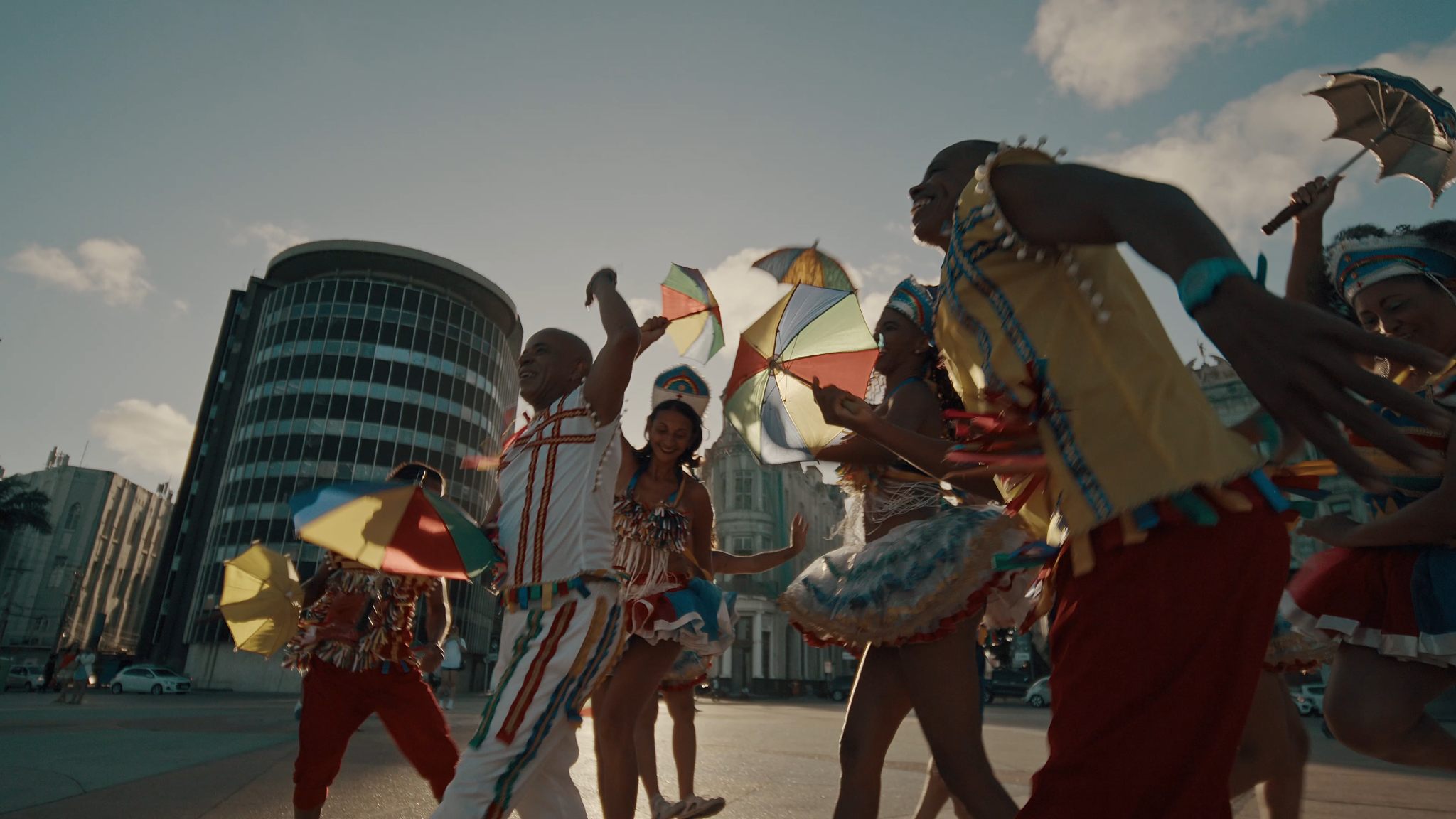Beyond the Algorithm: How Cultural Datasets Refine AI Imaging
Currently, the effectiveness of a Generative Artificial Intelligence model is not only measured by its processing capacity, but by the fidelity and context of the database that feeds it. However, we live in a “digital myopia” scenario: it is estimated that the vast majority of the data used to train global AIs comes from the Northern Hemisphere. The result is a technology that, although powerful, delivers generic and sometimes cartoonish results when it comes to the plurality of the Global South.
For image generation to reach a new level of precision and real utility, the transition from raw data to a structured cultural dataset is the indispensable path.
The Problem of Homogeneous Sampling
Models trained with predominantly eurocentered data tend to suffer from structural biases. When a user requests the image of a “family lunch” or a “popular celebration”, AI often resorts to aesthetic patterns and social contexts that do not reflect Brazilian reality.
This limitation isn't just an aesthetic flaw; it's an infrastructure gap. Without data sets that understand the nuances of territories, skin tones, gestures, and local architecture, the tool remains unable to generate images that have cultural legitimacy.
Culture as a Technical Layer
Unlike what you might imagine, the use of cultural data in AI is not a decorative resource; it's a layer of technical precision. Imaging effectiveness depends on processes such as:
Sovereignty and the Construction of the Imaginary
Betting on Brazilian datasets is, above all, a movement of digital sovereignty. By structuring our own cultural assets as infrastructure for technology, we ensure that the wealth generated by this data circulates within the national ecosystem and that our identity is not “translated” by foreign algorithms that do not know us.
When machines learn to see the world through eyes situated in our own reality, technology ceases to be just a tool for importing stereotypes to become a faithful mirror of our complexity.
[Image Insert: Representation of a multimodal dataset, showing layers of metadata superimposed on a Brazilian cultural scene]
The Future of the Situated Image
The refinement of generative AI necessarily involves the diversity and quality of the curatorship. Models that use structured cultural datasets not only generate better images; they build bridges between technological innovation and the real identity of peoples.
It is in this field, where technology meets the depth of the local repertoire, that Bamboo Data operates. Observing the need for data that respects our sovereignty and plurality, the company is dedicated to organizing this fundamental layer of information, ensuring that the development of Brazilian artificial intelligence has, above all, roots and context.
Proudly member of Nvidia Inception Program